Die heutige Datenkommunikation setzt immer mehr auf den plattformunabhänigen und leicht erweiterbaren Standard XML. Dies sieht man zum Beispiel an EDI (Electronic Data Interchange Standard), der nun durch den XML-EDI Standart abgelöst wird. Daten, die über diese neue Technologie ausgetauscht werden, wollen auch gespeichert werden. Da XML die Möglichkeit bietet, Informationen über das Dokument in dem Dokument, genauer: in den Tags, zu speichern, wird eine neue Art der Speicherung benötigt.
Am Anfang war das Dokument - Ende der sechziger Jahre wurde die Generalized Markup Language (GML) von Charles Goldfarb, Edward Mosher und Raymond Lorie erfunden; Ende der achtziger wurde dann die Fortführung in Form von SGML als Standard verabschiedet. Es ging darum, die Struktur von Dokumenten und deren Inhalt strikt voneinander zu trennen. Zwischen SGML und HTML war Platz für mehr. Die Frage war, wie man mehr als die paar HTML-Elemente ins Web bekommen könne. Die "Web SGML Activity", eine von Sun geförderte Gruppe, arbeitete in wenigen Monaten einen Entwurf aus, der alles Wesentliche enthielt. Ein großer Erfolg war, dass mit Microsoft eine der führenden Firmen XML schon 1996 unterstützte. So konnte das World Wide Web Consortium (W3C) Anfang 1998 die Syntax der neuen Metasprache XML 1.0 als Recommendation verabschieden.
Wenn zum Beispiel im E-Commerce Geschäftsdaten nicht mehr per Papier sonder auf elektronischem Wege zwischen Datenbanksystemen transportiert werden sollen, so muss es Regeln geben, nach denen diese Dokumente strukturiert sind. An diese Regeln müssen sich die Geschäftspartner halten. Am besten, es gelten allgemein gültige Standards, an die sich alle halten können. Die UN-Gruppe für Handelserleichterungen sowie E-Business (UN/ CEFACT) und die Organization for the Advancement of Structured Information Standards (OASIS) haben sich zusammengetan, um unter dem Namen ebXML einen Rahmen für die Struktur elektronischer Geschäftsdaten zu erarbeiten (www.ebxml.org).
Das Web drohte fragmentiert zu werden, da viele Browserhersteller die Zahl der HTML-Elemente hochschrauben wollten. Und Webdesigner hatten die Präsentation ihrer Seiten tief mit deren Struktur verwoben: in verschachtelte Tabellen, unsichtbare Grafiken etc. XML passte hier aufgrund seiner einfachen Implementierbarkeit und seiner Eigenschaft, den eigentlichen Inhalt und die Formatierung von Dokumenten strikt zu trennen. Und als Ende 1999, Anfang 2000, Webmaster WAP-Handys den Zugriff auf ihre Daten über die Wireless Markup Language (WML - eine XML Anwendung) ermöglichten, stellte sich eine Frage neu: Wie sorgen Autoren dafür, dass ihre Dokumente immer erreichbar sind, unabhängig davon, ob Anwender zum Beispiel blind oder taub sind bzw. wie wird der Inhalt so formatiert, dass verschiedenste Geräte ihn darstellen können? Wenn Inhalte geräteunabhängig vorgehalten werden, so spielt WML und eine Weiterentwicklung von HTML eine wichtige Rolle: die Extensible Hypertext Markup Language (XHTML) ist eine Neuformalierung von HTML, nur nicht mehr in SGML sondern in XML.
Mit XML können heute fast alle wichtigen Sprachen umgehen, so C, Perl, Python, PHP oder Java. In Gnome ist eine XML-Bibliothek integriert, Sun hat XML in seine Java Pläne aufgenommen. Das Apache-Projekt Cocoon ermöglicht die dynamische Auslieferung von XML über Servlets und Microsoft war von Anfang an bei der Entwicklung von XML dabei. Auch gehören Datenbanksysteme zu den Werkzeugen, die XML verarbeiten können. RDBMS Hersteller Oracle bietet Interessierten auf technet.oracle.com Informationen und Tools. Erste 'echte' XML-Server sind ebenfalls auf dem Markt; hier soll Tamino von der Software AG behandelt werden.
Die Extensible Markup Language dient in zunehmendem Maße als Austauschformat zwischen verschiedenen Informationsservern, da sie zum einen ein akzeptierter Standard zur Anordnung von Daten ist und zum anderen leicht via HTTP übertragen werden kann, da es sich ja um Plain- Text handelt. So muss es auch Mittel und Wege geben, XML-Dokumente zwischen Datenbanksystemen auszutauschen, sie in geeigneter Weise zu generieren bzw. abzulegen und Anfragen an sie zu richten. Das Relationenkonzept prägt jedoch die Welt der Datenbanken, und beim Mapping von XML-Daten in die Tabellen eines RDBMS ergeben sich gravierende Probleme. XML-Dokumente kann man aufgrund von strukturellen Merkmalen in folgende zwei Kategorien aufteilen:
Sie haben eine gleichmäßige, reguläre, nicht sonderlich tief verschachtelte Struktur. Die in
ihnen gekapselten Daten lassen sich leicht in kleinere Blöcke aufteilen, die dann als
geschlossenes Ganzes betrachtet werden können. Weiterhin tritt Mixed Content selten oder gar
nicht auf, und die Abfolge der Geschwisterelemente ist egal. Bei dieser Kategorie
von Dokumenten spielt der hierachische Aufbau von XML eine untergeordnete Rolle. Ein
Beispiel:
<?xml-version="1.0" encoding="UTF-8"?>
<order id="253639">
<customer id="2925">
<firstName>Andrea</firstName>
<lastName>Koehnes</lastName>
<street>Rennweg 9</street>
<city>Marburg</city>
<zipCode>94034</zipCode>
</customer>
<purchaseList>
<item id="0596000162" type="book">
<label>Schlafes Bruder</label>
<quantity>1</quantity>
</item>
<item id="2603658914" type="audio-cd">
<label>Fat of the Land</label>
<quantity>1</quantity>
</item>
</purchaseList>
<date>240301:1435</date>
</order>
Hier sind die Wesensmerkmale von XML nicht sonderlich stark ausgeprägt, und diese Dokumente lassen sich relativ einfach in Relationen transformieren. Die Verwendung von XML ist alles andere als zwingend, um solche Daten auszutauschen. Es gäbe hier sicherlich noch mehr Möglichkeiten, die Daten geeignet zu repräsentieren.
Sie haben eine unregelmäßige Struktur mit beliebig tiefen Verschachtelungen und Mixed
Content. Weiterhin ist die Abfolge der Geschwisterelemente signifikant, so dass ein
Vertauschen der Abfolge der Geschwister einer semantischen Änderung gleichkommt. Auch ist
eine Aufteilung in unabhängige Einheiten nur bedingt möglich. Ein Beispiel in XHTML:
<body>
<div>
Diese Seite enthält Produktinformationen zum neuen
Softwarepaket<b>HolyGrailv1.0</b>der Firma<i>Acme
Inc.</i>
</div>
<table>
<tr>
<td> Features der Software ...
</td>
<td>
<table>
<tr>
<td> <img src = "hg.gif" />
</td>
</tr>
<tr>
<td> Preis: 139,99 DM
</td>
</tr>
</table>
</td>
</tr>
</table>
</body>
Wie angesprochen, ist die Dekomposition eines datenzentrischen Dokuments relativ einfach, während die Struktur eines dokumentenzentrischen Typs nur schlecht vertikalisiert werden kann. Auch eine Auflösung der Verschachtelung ist nur bedingt möglich, sie würde zu einer semantischen Änderung führen. Und SQL ist für das Abfragen eines solchen Dokuments ungeeignet. Wird in einer DTD beipielsweise eine Rekursion definiert, so lassen sich Dokumente mit beliebiger Verschachtelungstiefe erstellen. Um diese zu erfassen, müsste man die transitive Hülle der Elemente berechnen. Diese Möglichkeit besteht bis einschließlich SQL 2 nicht. Oracle bietet zwar Erweiterungen des SQL-Standards an, jedoch sind diese weder allgemein gültig noch standardisiert. Trotzdem gibt es in allen gängigen RDBMS Möglichkeiten, XML-Dokumente zu verarbeiten, in Relationen zu pressen, XML aus Daten einer Tabelle zu formen und die Daten abzufragen.
Diese Wandlung ist recht einfach und geht ohne größere Probleme vonstatten. Es sind zwei Wege denkbar. Beim modellbasierten Verfahren bilden XML-Elemente das Schema und die Extensionen der Ergebnistabelle einfach nach; generiert wird ein Dokument des datenzentrischen Typs:
<table>
<row>
<col1>
... </col1>
<col2> ...
</col2>
...
</row>
</table>
Beim Template-basierten Verfahren läuft es anders. Es existiert ein XML-Dokument mit speziell ausgezeichneten Elementen, in die SELECT-Statements eingebettet sind. Diese werden ausgeführt und die zurückgegebenen Daten bei der Generierung des Ergebnisdokuments direkt an die entsprechende Stelle geschrieben. Bei beiden Verfahren wird die Mächtigkeit von XML nicht ausgenutzt, es dient hier lediglich als eine Art Wrapper.
Das große Problem auf diesem Weg ist die Frage, wie hierachisch aufgebaute, oft keiner regulären Struktur unterworfene XML-Daten in flachen Relationen ausgedrückt werden können. Die Transformation von datenzentrischen Dokumenten kann relativ leicht vollzogen werden, nicht aber die von dokumentorientierten, da bei diesen alle Eigenschaften von XML zum Tragen kommen. Die einfachste Möglichkeit ist, das gesamte Dokument in einer einzigen Spalte als Binary Large Object (BLOB) abzulegen. Hier gibt es keine Probleme bei der Speicherung, wohl aber bei der Abfrage dieses Dokuments. Auch ist es schwer, neue Dokumente aus Teilen eines existierenden, in der Datenbank abgelegten Dokuments zu erzeugen. Für einfache Anwendungen reicht diese Vorgehensweise jedoch aus. Ein weiterer Ansatz ist folgender: Zentrales Problem bei der Speicherung ist die Abbildung des DOM-Baumes (Document Object Model) auf Relationen. Für jedes Teilobjekt des DOM werden eigene Tabellen erzeugt, die dann mit Primär- und Fremdschlüsseln miteinander verknüpft werden, was die Struktur des DOM nachahmt. Jede darzustellende Ausprägung eines derartigen Teilobjekts eines DOMs nimmt eine Tabellenzeile in Anspruch, was speicheraufwendig sein kann. Die hohe Zahl an Joins verringert die Performance eines solchen Systems. Nachteilig ist außerdem die schlechte Erweiterbarkeit. Weiter wird ein mitunter einfaches XML-Dokument durch eine große Anzahl von Tabellen aufgebläht.
Relationale Datenbanken erzeugen Kontext für Daten durch Tabellen, Joins und andere Beziehungen, können aber nicht mit der Hierachie und den mit Metadaten gefüllten XML- Dokumenten umgehen. Alle gängigen Datenbankhersteller bieten für ihre Produkte Erweiterungen an, um XML-Daten auszutauschen und zu speichern. Hier kommen die oben vorgestellten Techniken wie das Modell- oder das Template-basierte Verfahren zum Einsatz. Es handelt sich aber hierbei eher um Ad-hoc-Lösungen, die vornehmlich auf den Einsatz von datenzentrischen Dokumenten ausgerichtet sind. Dokumente der Gattung Document-Centric sind in der Regel in einer Spalte der Tabelle als Blob abgelegt. Diese Erweiterungen können nicht zufriedenstellen, wenn es bei einem System darum geht, Dokumente im eigentlichen Sinn auszutauschen. Im Folgenden soll die XML-Datenbank Tamino der Software AG erläutert werden, die die genannten Probleme löst und eine für hierachisch angeordente Daten geeignete Abfragesprache bietet, wie zum Beispiel X-Path.
Der Tamino XML Server ist ein Informationsserver, der XML benutzt, um XML Daten von verschiedenen Quellen zu speichern und dann die Möglichkeiten der XML Transformation ausnutzt, um die gespeicherten Daten in vielfältiger Weise auszugeben. Der haupsächliche Vorteil von Tamino besteht darin, dass er die XML Daten unter Benutzung der Web und XML Spezifikationen nativ abspeichert. In die schon bestehende Infrastruktur von Webservern und Applikationsservern bettet er sich sauber ein. Ein solcher nativer Datenbankserver benutzt XML Standards: das XML Dokument ist die fundamentale Einheit der Speicherung; DTDs oder Schemas beschreiben die Struktur eines solchen Dokuments und XPath oder andere XML- spezifische Abfragesprachen lokalisieren die Daten.
Tamino arbeitet typischerweise in einer Windows-, Unix oder Mainframeumgebung und benutzt die erhältlichen Industriestandards für Kommunikation. Folgende Funktionen sind eingebaut (in Klammern die verantwortliche Komponente):
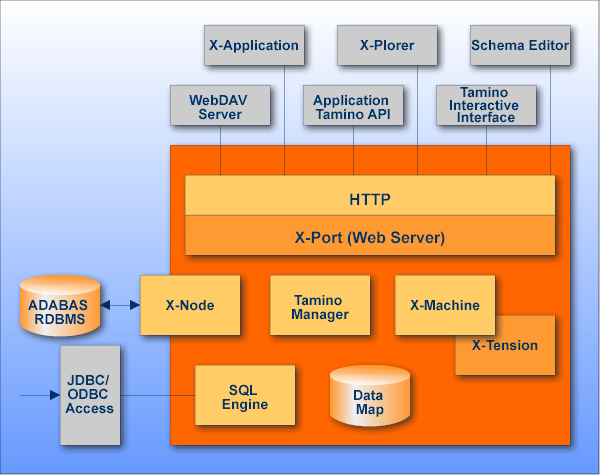
Tamino besteht aus 2 Hauptteilen: dem Tamino XML Server und den Produktkomponenten, die auch
als Standalone Komponenten einzeln runtergeladen werden können:
Der Tamino XML Server besteht im wesentlichen aus 6 Komponenten, welche da wären:
Der Name deutet es an: Die X-Machine ist Dreh- und Angelpunkt von Tamino. Sie ist ein
DBMS für XML-Dokumente. Ihre haupsächliche Funktion ist das native Speichern von XML-Objekten
und umgekehrt das Auslesen aus nativen XML-Datenspeichern sowie verschiedenen anderen
Datenquellen. Dies geschieht aufgrund von Schemas, die vom Administrator definiert wurden.
Normalerweise werden XML-Objekte in Tamino gespeichert, aber Tamino unterstützt auch andere
externe Datenbanksysteme, die über ODBC oder das ADABAS System erreichbar sind. Für die
Speicherung und das Auslesen ist die X-Machine in weitere Subkomponenten gegliedert, wie die
Grafik zeigt:
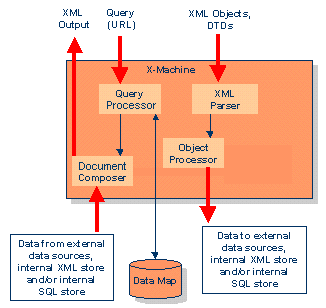
Eingehende Daten werden vom XML Parser auf syntaktische Richtigkeit überprüft und an den Object Processor weitergereicht.
Der Object Processor wird benutzt, wenn Daten gespeichert werden sollen. Die XML Instanzen werden gegenüber dem logischen Schema validiert; während das physische Schema die Art der Speicherung definiert.
Die Abfragesprache ist X-Query. Der Query Prozessor optimiert die Abfrage anhand des gegebenen Schemas.
Der Document Composer tritt in Aktion, wenn die XML Informationen zusammengestellt werden müssen. Unter Benutzung der Speicher- und Ausgaberegeln, die in der Data Map festgehalten werden, bildet er die Informationseinheiten und gibt sie als XML-Dokument zurück. Der einfachjste Fall ist, wenn das auszugebende Objekt intern als XML gespeichert wurde. Komplexer wird es, wenn mit dem X-Node kommuniziert werden muss, um ein XML-Objekt aus nicht- XML Quellen zu generieren.
Der X-Node ist die Schnittstelle zu externen Datenspeichersystemen:
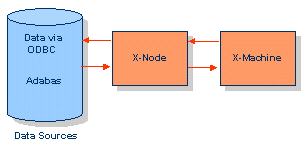
Das X-Node-System ermöglicht es, bereits existierende Datenbanken verschiedenster Hersteller
und Lokalität einzubinden. Somit kann durch eine einzige Abfrage an Tamino eine Reihe von
Daten aus anderen Datenbanken zu den in Tamino gespeicherten hinzugefügt werden und als ein
einziger Datensatz zurückgeliefert werden, ohne Datenbanken zu spiegeln oder umzustellen. Der
Zugriff geschieht via ODBC und ist daher auf verschiedenste Server möglich. Somit kann Tamino
als zentraler Server für existierende Datenbanken über das Web agieren.
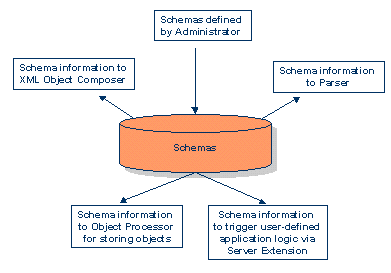
Die Data Map ist das Repository. Sie enthält alle XML Meta Informationen, XML Schemas und
das Mapping zu relationalen Schemas. Sie bestimmt, wie XML-Objekte auf physikalische
Datenstrukturen gemappt werden, seien sie intern oder extern lokalisiert. So können externe
Datenbanken die XML Technologie nutzen. Daher enthält die Data Map Informationen, die für
folgende Funktionen benötigt werden:
Die SQL Engine verwaltet die relationalen Tabellen in der Datenbank und führt SQL-Abfragen
durch:
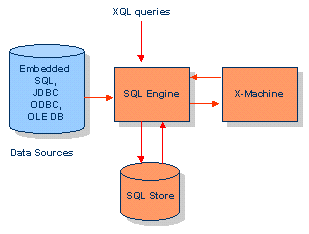
Die Abfragen können die SQL Engine auf verschiedenen Wegen erreichen:
Über den Tamino Manager wird der Tamino Server administriert:
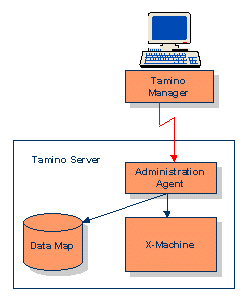
Der Tamino Manager ist als Client-Server Anwendung konzipiert worden und stellt eine GUI zur
Verfügung, die in jedem gängigen Web-Browser läuft. Einen Eindruck über die Funktionen und
die Bedienung soll folgender Screenshot geben:
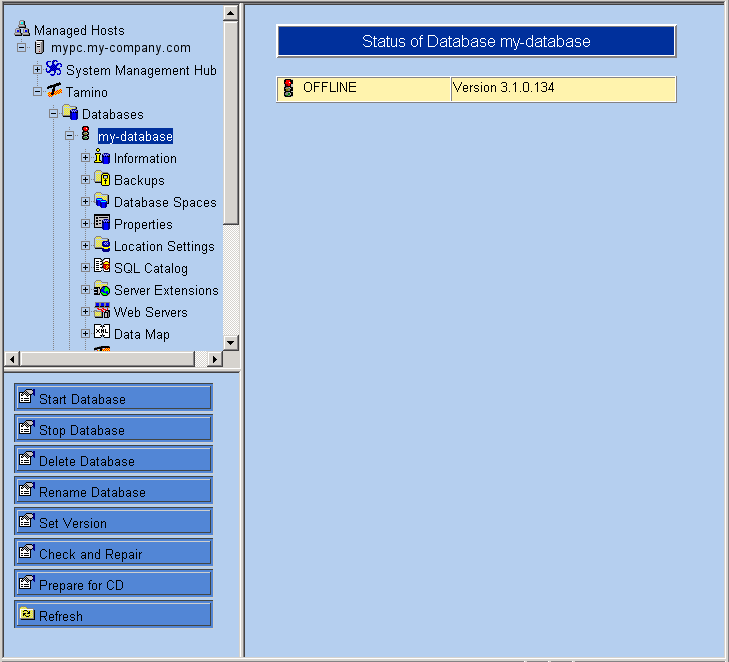
Neben den grundsätzlichen Funktionen (Anlegen von Datenbanken, Start/Stopp, Backup,
...) bietet der Tamino Manager die Möglichkeit des Zugriffs auf die Data Map, um z.B. Schemas
zu konfigurieren.
Benutzer können in C oder C++ eigene Erweiterungen definieren, die über die X-Tension
aufgerufen werden. Diese werden Server Extensions genannt.
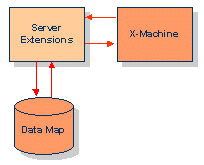
In der Data Map kann in einem Schema definiert werden, dass ein XML Objekte auf solche
benutzerdefinierte Funktionen "gemappt" werden. Diese werden immer dann aufgerufen, wenn ein
eingehendes Objekt geparst wird oder wenn ein Objekt geholt wird. Ein Beispiel für eine
solche Funktion wäre, wenn Daten auf eine ganz bestimmte Art und Weise behandelt werden
müssen, die den Standard Funktionen entgegensteht.
Die Server Extensions werden über den Tamino Manager installiert. Einmal eingebaut sind sie
für den Endbenutzer nicht mehr von Tamino's Standard Funktionen unterscheidbar.
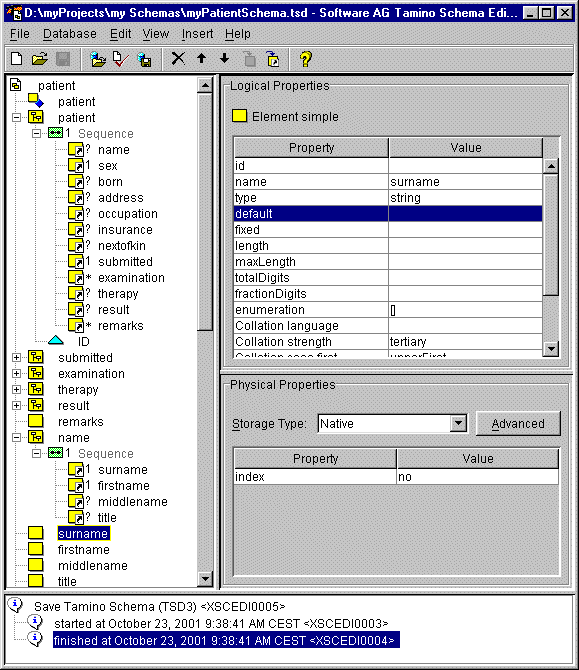
Der Schema Editor ist ein grafisches Produkt, das bei einer typischen Installation von Tamino enthalten ist. Es hat die Aufgabe, dem Administrator bei der Erstellung von Tamino Schemas (Tamino Schema Definition Language 3 - TSD3) zu helfen. Mit diesem Produkt ist es nicht erforderlich, die Schema Syntax genau zu beherrschen, da der Editor mit dem Administrator über Dialoge kommunizieren und Schemen automatisch generieren kann. So wird Fehlern vorgebeugt und die Erstellung geht schneller vonstatten. Im folgenden soll nun etwas näher auf XML Schema und TSD3 eingegangen werden.
XML Schema beschreibt die Struktur von XML Dokumenten in XML. So können beispielsweise in einem
XML Schema festgelegt werden, welche Kindelemente ein Superelement hat, wie diese angeordnet sind,
welche Attribute ein Element hat, deren Standardwerte u.v.m. TSD3 ist konform zu XML Schema,
enthält jedoch noch weitere Tamino-spezifische Informationen. Wie aber sieht ein Schema aus? Um dies
zu illustrieren, benutzen wir ein Beipiel aus dem Krankenhaus. Es soll eine Datenbank existieren, die
Informationen über Patienten speichert. Dies könnte (nicht vollständig) so aussehen:
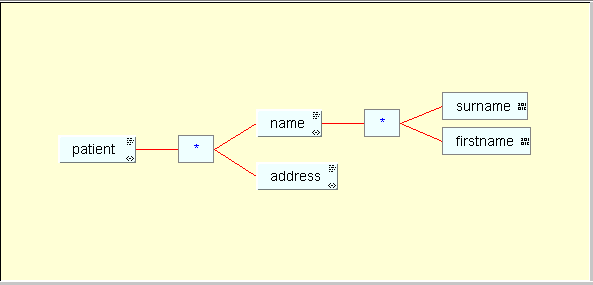
Diese Struktur wird von folgendem XML Schema repräsentiert:
<xs:schema xmlns:xs ="http://www.w3.org/2001/XMLSchema">
<!--
Schema for patient data. This could be a fragment of a larger DTD modelling
hospital data -->
<xs:element xs:name='patient'>
<xs:complexType>
<xs:sequence>
<xs:element
xs:ref='name' xs:minOccurs='0'/>
<xs:element xs:ref='address' xs:minOccurs='0'/>
</xs:sequence>
<xs:attribute xs:name='ID'
xs:type='string' xs:use='optional'/>
</xs:complexType>
</xs:element>
<xs:element
xs:name='name'>
<xs:complexType>
<xs:sequence>
<xs:element
xs:ref='surname'/>
<xs:element
xs:ref='firstname'/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element
xs:name='surname' xs:type='string'/>
<xs:element xs:name='firstname'
xs:type='string'/>
<xs:element xs:name='address'>
<xs:complexType>
<xs:sequence>
<xs:element
xs:ref='street' xs:minOccurs='0'/>
<xs:element xs:ref='housenumber'
xs:minOccurs='0'/>
<xs:element
xs:ref='city' xs:minOccurs='0'/>
<xs:element xs:ref='postcode'
xs:minOccurs='0'/>
<xs:element
xs:ref='country' xs:minOccurs='0'/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element
xs:name='street' xs:type='string'/>
<xs:element xs:name='housenumber'
xs:type='string'/>
<xs:element xs:name='city'
xs:type='string'/>
<xs:element xs:name='postcode'
xs:type='string'/>
<xs:element xs:name='country'
xs:type='string'/>
</xs:schema>
Um ein Schema für Tamino zu definieren, sind 2 Schritte notwendig:
Der Tamino X-Plorer ist eine weitere Produktkomponente im Lieferumfang vom Tamino. Hierbei handelt es sich um
einen Administrationsmodul in Form einer Java-Anwendung, die vom "look and feel" - der Handhabung und dem Aussehen -
sehr dem Windows-Explorer ähnelt und somit recht intuitiv zu Bedienen ist.
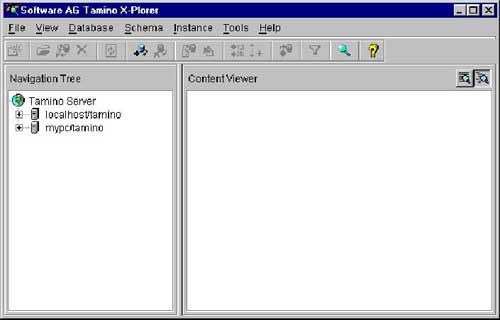
Der X-Plorer repräsentiert die Inhalte des Servers in einer Baumstruktur
und ermöglicht das "Browsen" durch die Datenbankinhalte. Auf diese Weise können Daten angesehen, verändert oder gelöscht werden.
Im folgenden drei Anwendungsbeispiele:
Übersicht über die Datenbankinhalte
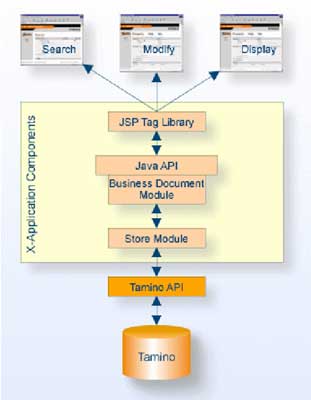
Hier werden nötige Schnittstellen bereitgestellt, um über die Browserschnittstelle auf die Inhalte der Datenbank zuzugreifen. Unterstützt werden
SOAP-Nachrichten und die Einbettung von Datenbankinhalten in Webseiten über speziell definierte JSP-Tags. Zur Unterstützung anspruchsvoller Geschäftslogiken
kann Tamino auch über Enterprise Java Beans angesprochen werden. Die folgende Grafik enthällt eine entsprechende Übersicht:
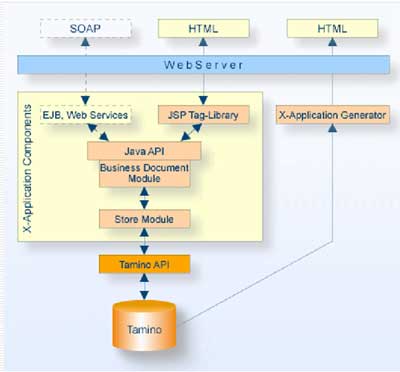
Von besonderem Wert für kleine Anwendungen und schnelle Lösungen ist die JSP Tag Library. Da JSP eigene Erweiterungen zulässt, war die Implementierung einer
solchen Library für Tamino mehr als naheliegend. Mit ihr können Datenbankzugriffe auf einfache Weise in HTML Seiten eigebettet werden, und es stehen sämtliche
Mittel zur Operation auf der Datenbasis zur Verfügung. Plugins für kommerzielle Entwicklungsumgebungen zur einfachen Verwendung dieser Tags sind ebenfalls
vorhanden.
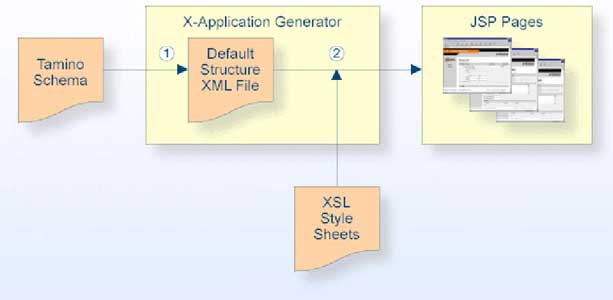
Mit der X-Application Schnittstelle und der JSP-Tag Library sind die Grundlagen gelegt, Applikationen auch weitesgehend automatisch generieren zu lassen.
Genau diese Aufgabe übernimmt der X-Application Generator. Er erstellt automatisch aus XML Dateien und zugehörigen XSL Style Sheets Java Server Pages.
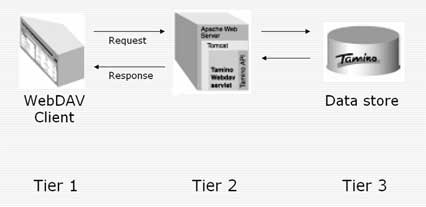
// URI der Tamino-Datenbank
public final static String DATABASE_URI = "http://localhost/tamino/myDB";
// XML-Dokuments
public final static String XML = "
// XML-Inhalt in einen StreamReader
StringReader stringReader = new StringReader( XML );
// Instantiierung eines leeren TXMLObject nach DOM
TXMLObject xmlObject = TXMLObject.newInstance( TDOMObjectModel.getInstance() );
// Fertigstellen der DOM-Repräsentation durch Lesen des Inhalts
xmlObject.readFrom( stringReader );
// Verbindungsaufbau
TConnection connection = TConnectionFactory.getInstance().newConnection( DATABASE_URI );
TXMLObjectAccessor xmlObjectAccessor = connection.newXMLObjectAccessor(
TAccessLocation.newInstance( "ino:etc" ),
TDOMObjectModel.getInstance() );
// Einfuegeoperation
xmlObjectAccessor.insert( xmlObject );
// Anzeige der zugehoerigen ino:id
System.out.println( "Insert succeeded, ino:id=" + xmlObject.getId() );
// Vorbereitung des Lesens der Instanz
TQuery query = TQuery.newInstance( xmlObject.getDoctype() + "[@ino:id=" + xmlObject.getId() + "]" );
// Abfrage
TResponse response = xmlObjectAccessor.query( query );
if ( response.hasFirstXMLObject() ) {
StringWriter stringWriter = new StringWriter();
response.getFirstXMLObject().writeTo( stringWriter );
System.out.println( "Retrieved following instance:" + stringWriter );
}
else
System.out.println( "Keine Instanz gefunden!" );
connection.close();
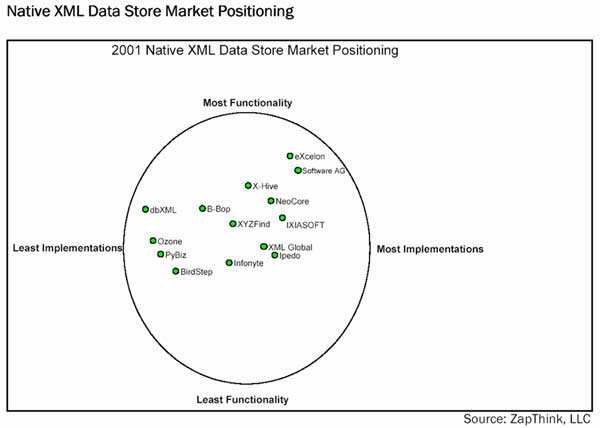
Größter Funktionsumfang entfällt auf die XML DB eXceleron
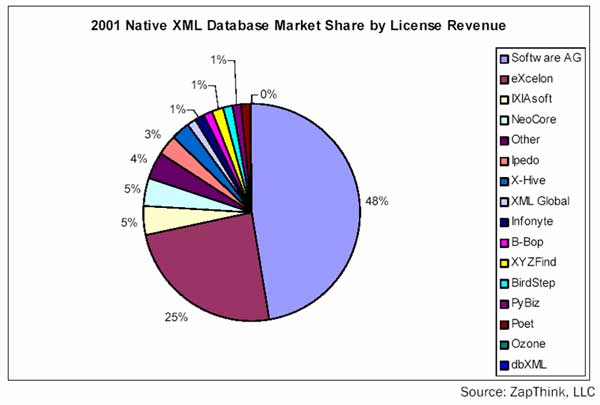
Spitzenreiter bei den vergebenen Lizenzen ist TAMINO
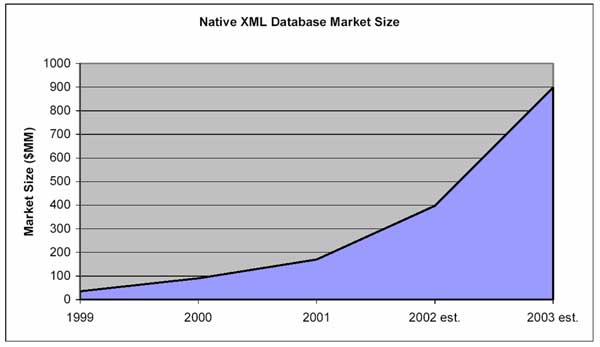
Geographische Verteilung der XML DB: Auf Europa / mittlere Osten und Afrika fällt der größte Anteil
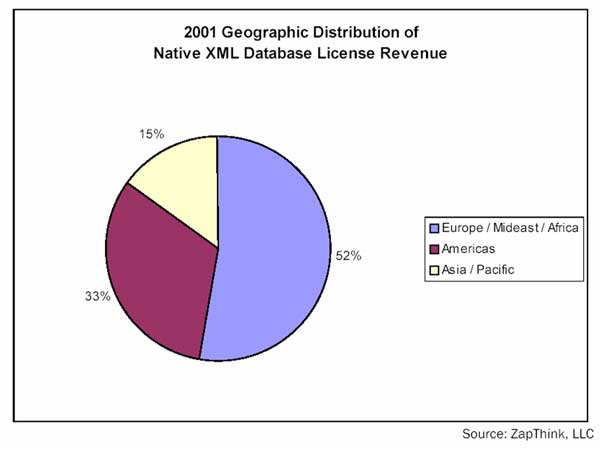
Die von den Herstellern erwartete bzw. erhoffte Marktentwicklung am Markt der nativen XML Datenbanken. Sollte dies zutreffen, dann müssten wir alleine dieses Jahr fast mit
einer Verdoppelung des Marktes rechnen.