Diese Seminarausarbeitung entstand im Rahmen des Multimediaseminars im Wintersemester 2001/2002 des Fachbereiches MNI der Fachhochschule Gießen - Friedberg. Das Seminar wurde durchgeführt von Prof. Dr. Kneisel und Prof. Dr. Christidis. Die Vortragsdauer betrug ca. 60 Minuten. Die Präsentation zum Vortrag kann hier herunter geladen werden: DOM.ppt
Die Abkürzung DOM steht für Document Object Model. Eine Übersetzung ins deutsche bedeutet soviel wie Objektorientiertes Dokumentenmodell. Unter der Abkürzung DOM verbergen sich jedoch zwei Bedeutungen. Spricht man von diesem so muß unterschieden werden welche der beiden Bedeutungen gerade gemeint ist. Es ist zum einen ein Objektorientiertes Modell zur logischen Darstellung von Informationen aller Art, und zum anderen eine Schnittstellendefinition die es erlaubt in einem solchen Modell sich zu bewegen, Informationen aus dem Modell zu lesen und dieses Modell zu manipulieren. Unter Manipulation versteht man das Hinzufügen, Verändern oder Entfernen von Informationen aus einem solchen Modell.
Das DOM definiert in erster Linie eine logische Struktur für XML - Dokumente. Im allgemeinen wird jede Form von Daten, die mit Hilfe von XML strukturiert werden kann als Dokument im Sinne des DOM angesehen. Das bedeutet dass auch HTML - Dokumente gültige Dokumente im Sinne des DOM sind, da HTML durch eine passende XML - Sprachdefinition abgebildet werden kann. Welche Informationen und wie man Informationen aller Art in XML strukturieren kann und damit als ein DOM ansehen kann soll der Abschnitt Daten in "DOM - Form" verdeutlichen.
XML steht für Extensible Markup Language. Es ist eine vom W3C definierte und vereinfachte Teilmenge von SGML. Wie SGML wird auch XML als Metasprache verwendet, um eigene Sprachen zu definieren. Im Gegensatz zu SGML ist XML bedeutend einfacher so dass praktisch jeder in der Lage ist eigene XML - Formate zu definieren während bei SGML Expertenwissen verlangt wird.
Mittels XML können Informationen strukturiert in Textdateien abgelegt werden. Für diesen Zweck wird eine Maßgeschneiderte Menge von Tags geschaffen die, die Informationen strukturiert und beschreibt.
Ein Tag besteht dabei normalerweise aus einem öffnenden und einem schließenden Tag. Zwischen den Tags befindet sich die Information. Durch Attribute innerhalb des öffnenden Tags können zusätzlich Informationen über die eigentlichen Informationen abgelegt werden. Enthält ein Tag keine Informationen so kann das schließende Tag weggelassen werden falls das öffnenden Tag speziell gekennzeichnet ist. Die Tags können beliebig ineinander verschachtelt werden.
Die Definition eines Elements sieht laut dem W3C wie folgt aus:
element ::= STag content ETag | EmptyElemTag
Zuerst der normale Fall, indem der Tag aus einem öffnenden und einem schliessenden Tag besteht.
STag ::= '<' Name (Attribute)* '>'
Attribute ::= Name Eq AttValue
ETag ::= ''
content ::= (element | CharData | Reference | CDSect | PI | Comment)*
Eq ::= '='
Die Definition der Variante ohne content ist viel kürzer:
EmptyElemTag ::= '<' Name (Attribute)* '/>'
Die oberen Definitionen sind unvollständig und sollen lediglich das Prinzip verdeutlichen. Die genaue und vollständige Definition des XML-Standards ist auf der Seite des W3C zu finden.
Obwohl in XML man die Möglichkeit hat Tags und deren Attribute frei zu definieren müssen XML - Dokumente einigen wenigen allgemeinen Regeln entsprechen. Ein XML - Dokument heißt demnach wohlgeformt (well formed), wenn zumindest alle Tags geschlossen werden, die auch geöffnet wurden, wenn die Verschachtelung in korrekter Reihenfolge erfolgt. Alle XML - Dokumente, die auf irgendeine Weise von Computerprogrammen bearbeitet werden sollen müssen zumindest wohlgeformt sein.
Das folgende Beispiel zeigt ein einfaches XML - Dokument das einen Telefonbucheintrag darstellt.
<?xml version="1.0" encoding="UTF-8"?>
<person>
<name>Becker</name>
<vorname>Heinz</vorname>
<vorwahl>12345</vorwahl>
<anschluss>98765</anschluss>
</person>
Mit Hilfe einer DTD (Document Type Definition) können weitere Bedingungen an die Struktur eines XML - Dokumentes formuliert werden. So kann die Verschachtelung der einzelnen Tags genau bestimmt werden, oder welche Werte bestimmte Attribute enthalten dürfen. Dokumente die eine DTD besitzen und den Bedingungen genügen sind gültig (valid).
Mehr zu XML und der Syntax von XML ist der XML - Spezifikation des W3C zu entnehmen.
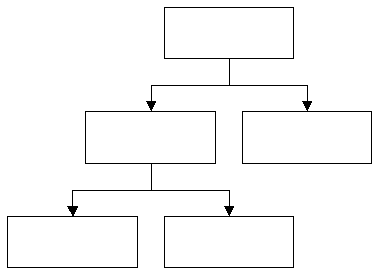
Ein Document Object Model ist eine Hierarchische Struktur von Elementen die Knoten genannt werden. Diese Struktur hat einen Wurzelknoten der beliebig viele Nachfolger haben kann. Jeder Nachfolger ist ebenfalls ein Knoten und kann ebenfalls beliebig viele Nachfolger haben. Das Document Object Model stellt damit einen Baum dar. Ein solcher Baum entspricht der hierarchischen Struktur eines XML - Dokumentes.
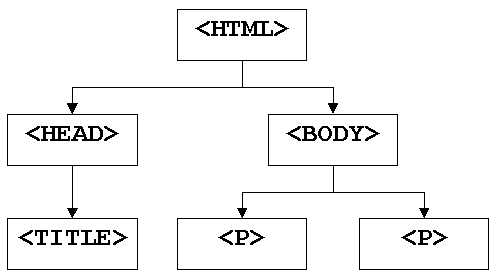
Wird ein DOM aus einem vorhandenem XML - Dokument erzeugt so entspricht jeder Knoten einem Tag des Dokumentes. Das Wurzelelement eines XML - konformen HTML - Dokumentes würde dem nach ein Konten mit dem Namen HTML sein. Dieser Knoten hätte als Nachfolger die Knoten HEAD und BODY. Diese Knoten enthalten wiederum weitere Knoten gemäß der Spezifikation.
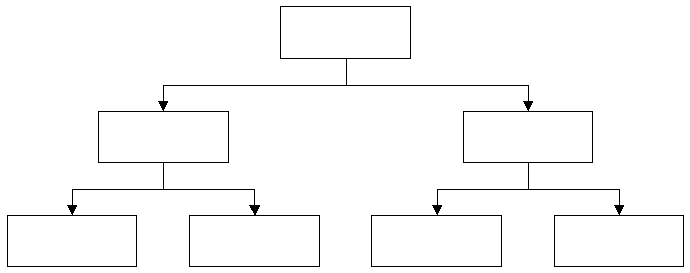
Durch besondere Definitionen in der DTD eines Dokumentes kann die Baumstruktur beeinflusst werden. Durch Einschränkungen der Struktur können zum Beispiel besondere Formen von Bäumen erzeugt werden. Erlaubt man jedem Knoten nur zwei Nachfolger, so entsteht ein Binärer Baum.
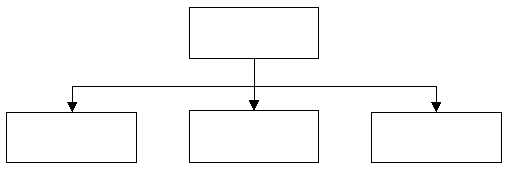
Enthält ein Knoten als Nachfolger nur Knoten des gleichen Typs, so entspricht das einer Liste.
Die Informationen sind in den Knoten gespeichert und werden durch den Knotentyp und durch die zusätzlichen Attribute der Knoten beschrieben und strukturiert.
Wie am Anfang erwähnt ist es mit Hilfe des DOM möglich DOM Strukturen zu lesen, zu modifizieren oder neu zu erstellen. Das bedeutet dass man einerseits Informationen aus strukturierten XML - Dokumenten verarbeitet und andererseits womöglich Informationen aus anderen Quellen bezieht und diese in einer DOM - Struktur abbilden muss.
So müssen unter Umständen Daten die ein anderer Prozess, der Benutzer oder eine Netzwerkverbindung liefert verarbeitet werden. Diese Daten werden Programmintern auf verschiedene Art und Weise gespeichert. Die Daten werden zur Laufzeit auf Variablen, Objekten, Arrays und andere Strukturen abgebildet.
Während der Softwareentwicklung muß der Entwickler, falls nicht bereits vorgegeben den Aufbau einer DOM - Struktur definieren. Was gleichbedeutend mit der Definition des XML - Dokumentes ist, das erzeugt werden soll. Der Entwickler muß die Elemente erkennen, die im XML - Dokument abgelegt werden sollen, sie gegebenenfalls logisch gruppieren. Vereinfacht gesagt muß er eine Abbildung der internen Strukturen auf eine DOM - Struktur vornehmen.
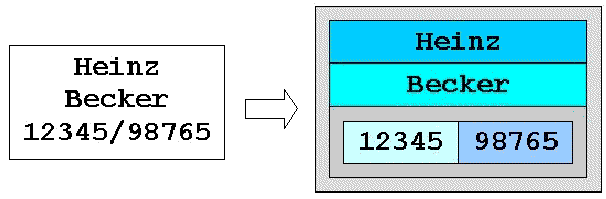
Der linke rechteckige Bereich entspricht der Gesamtmenge der abzubildenden Informationen. Durch Erkennen der einzelnen Elemente und logische Gruppierung der Elemente nach ihrer Bedeutung wird die Gesamtmenge in kleine Elemente unterteilt die dann in die Baumstruktur transformiert werden können.
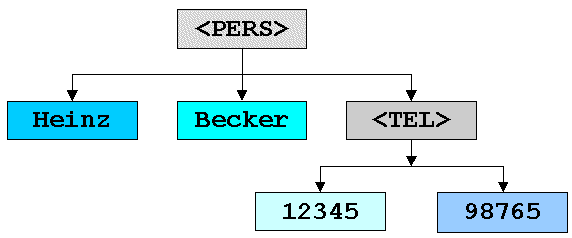
Das folgende Beispiel zeigt ein XML-Dokument, das eine News darstellen soll. Die farblich markierten Bereiche entsprechen einem Knoten in der XML - Struktur. Dabei umschließt der gelb markierte Knoten news die anderen drei Knoten title, body und author. Die umschlossenen Elemente sind die Kindknoten des Knotens news. Die drei einzelnen Knoten enthalten keine weiteren Knoten mehr und stellen damit die Blätter in der Baumstruktur dar.

DOM ist eine W3 Empfehlung die am 1. August 1998 in der Version 1.0 herausgegeben wurde. Das W3C wurde ursprünglich eingeschaltet um eine einheitlichen Sprachnorm für JavaScript zu erarbeiten. Grund dafür waren die verschiedenen Implementierungen von JavaScript in den verschiedenen Browsern. Die Ursprungsversion von JavaScript, die Netscape von der ECMA standardisieren ließ und somit schon recht früh zum Standard machte, wurde zwar von Netscape und Microsoft eingehalten doch die Browser hatten erhebliche Erweiterungen. Webprogrammierer waren gezwungen Browserabhängige Skripte zu entwickeln, das bedeutete oft die doppelte Entwicklungsdauer.
Das W3 - Konsortium erarbeitete jedoch bei ihrer Arbeit keinen konkreten JavaScript - Standard, sondern das DOM. Das Modell sollte eine Skriptsprache, die sich als Ergänzungssprache zu Auszeichnungssprachen wie HTML versteht, vollständig umsetzen. Ein wichtiger Aspekt des DOM ist, dass es nicht nur für HTML ergänzende Scriptsprachen konzipiert ist, sondern auch für Scriptsprachen, die jegliche XML - gerechte Auszeichnungssprache erweitern sollen. Das DOM orientiert sich daher in seinem Kern nicht mehr an bestimmten HTML - Elementen, Stattdessen geht es in abstrakter Weise von einem "Dokument" aus.
Da man bei der Entwicklung des DOM auch auf die Gegebenheiten und die Verbreitung von HTML und JavaScript Rücksicht nehmen wollte, wurde dem so genannten "Kern - DOM" (DOM Core) ein "HTML - Anwendungs - DOM" (DOM HTML) zur Seite gestellt.
Seit dem 13. November 2000 gibt es die Version 2.0 des DOM. Diese Version berücksichtigt Event - Handling sowie die Integration von Stylesheets. Die Version 3.0 befindet sich in der Entwicklung.
Wie in den vorherigen Abschnitten beschrieben definiert das Document Object Model eine logische Sicht auf ein XML, HTML oder allgemein ein Dokument dar. Die einzelnen Informationen werden in einem Baum dargestellt. Jeder Knoten des Baumes kann zusätzliche Attribute zu den eigentlichen Informationen enthalten.
Die DOM Core - Empfehlung stellt eine Menge von Schnittstellen zu Verfügung mit denen es möglich ist Informationen logisch in einem Baum darzustellen. Da das DOM den objektorientierten Ansatz verfolgt, kann hier von abstrakten Klassendefinitionen gesprochen werden.
Die Definitionen der DOM Core - Empfehlung legen die Klassenstruktur sowie die Methoden der einzelnen Klassen fest. Aufgrund der klaren Struktur und der detaillierten Beschreibung der einzelnen Klassen und Methoden sollte eine Implementierung in einer Objektorientierten Programmiersprache wie Java oder C++ relativ schnell und einfach zu Bewältigen sein.
Das folgende Diagramm zeigt die wichtigsten Klassen der DOM Core - Empfehlung und ihre Beziehung zu einander.
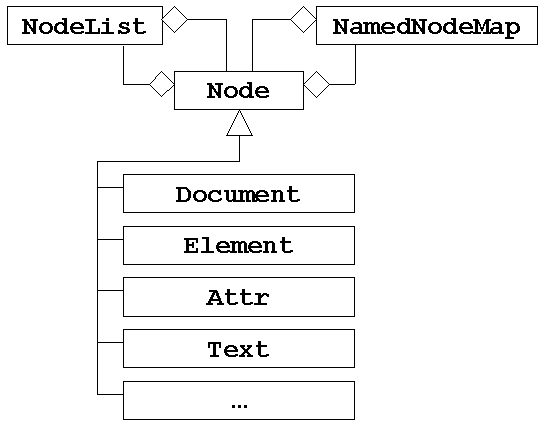
Da im DOM die Knoten beliebig viele Nachfolger haben können, definiert das DOM zwei neutrale Klassen die den Umgang mit Mengen von Knoten beschreiben. Die Definition sagt jedoch nichts über die Implementierung dieser aus.
Die Klassen sind:
Die wichtigste Klasse in der DOM Core - Empfehlung ist die Klasse Node. Node ist der Basistyp für alle anderen Knoten des DOM. Die Klasse stellt einen einzelnen Knoten des Baumes dar. In einer konkreten Implementierung wird die Klasse abstrakt implementiert, so dass keine konkrete Instanz von ihr direkt erzeugt werden kann.
Die wichtigsten Methoden der Klasse Node sind:
Es fällt auf, dass bereits an dieser Stelle Methoden definiert werden, die sich mit dem Umgang von Kindknoten beschäftigen, obwohl nicht alle Knotentypen Kinder haben Können. Außerdem werden Methoden definiert, die für unterschiedliche Knotentypen eine unterschiedliche Semantik haben. Diese Vorgehensweise ermöglicht eine sogenannte flache Sicht auf den Dokumentenbaum. Da jeder Knoten des Baums ein Node ist, kann relativ einfach durch den Baum navigiert werden, ohne Typkonvertierungen vornehmen zu müssen. Das ermöglicht eine schnelle und effektive Implementierung sowie vorteile im Laufzeitverhalten.
Diese Klasse beschreibt das gesamte Dokument. Über diese Klasse hat man Zugriff auf Informationen über das Dokument und auf das Wurzelelement des Baumes.
In konkreten Implementierungen ist diese Klasse ebenfalls als Abstrakt deklariert. Instanzen dieser Klasse müssen über sogenannte Fabriken erzeugt werden. Diese Vorgehensweise wurde gewählt um eine Implementierung in möglichst vielen Programmiersprachen zu ermöglichen.
Da alle Knoten eines Dokumentes nur in dessen Kontext existieren können enthält die Klasse diverse create...(...) Methoden die Knoten des Dokumentes erzeugen kann.
Die wichtigsten Methoden sind:
Element beschreibt, verglichen mit einer XML - Datei einen Tag daraus. Element erlaubt über seine Methoden bequemen Zugriff auf die Kindknoten und Attribute des Elements.
Die wichtigsten Methoden sind:
Die hier vorgestellten Definitionen und Methoden sind nicht vollständig und sollen nur einen Überblick über die einzelnen Schnittstellen und ihre Funktionsweise verdeutlichen.
Die DOM HTML - Empfehlung des W3C ist eine Erweiterung der DOM Core - Empfehlung. Die Empfehlung ist speziell auf HTML - Dokumente zugeschnitten. Sie enthält Elemente die, die den Umgang mit HTML - Dokumenten erleichtern sollen. Das DOM - HTML ist eigentlich das was Microsoft und Netsacpe seit Jahren versprechen in ihre Browser in Form von JavaScript zu integrieren. Beide Implementierungen sind jedoch wohl noch etwas unterschiedlich und unvollständig.
Das folgende Diagramm zeigt die Klassenstruktur des DOM - HTML.
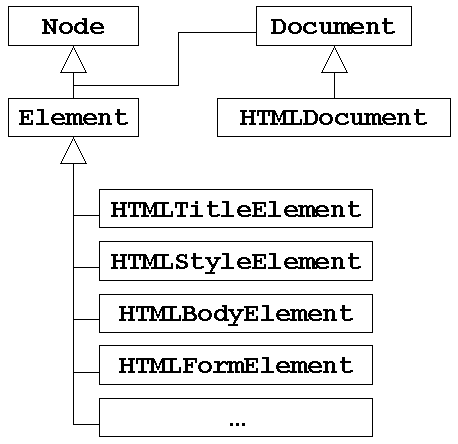
HTMLDocument ist von Document des DOM - Core abgeleitet und stellt das gesamte HTML - Dokument dar. Über das HTMLDocument erhält man Zugriff auf zusätzliche Informationen über das Dokument und dessen Elemente.
Die wichtigsten Eigenschaften und Methoden:
Über das HTMLDocument erhält man zusätzlich direkten Zugriff auf alle Bilder, Applets, Formulare, Links und Verweise des Dokumentes.
Das HTMLElement ist vom Element des DOM - Core abgeleitet und ist um einige wenige HTML spezifischen Eigenschaften erweitert worden.
Die exakte Definition des W3C für des Element HTMLElement sieht wiefolgt aus:
interface HTMLElement : Element {
attribute DOMString id;
attribute DOMString title;
attribute DOMString lang;
attribute DOMString dir;
attribute DOMString className;
};
Das HTMLBodyElement stellt den sichtbaren Inhalt einer HTML-Datei dar. Das Element besitzt keine Methoden, es besitzt nur einige Eigenschaften, die die Darstellung der Seite beeinflussen können.
Die exakte Definition des W3C für des Element HTMLBodyElement sieht wiefolgt aus:
interface HTMLBodyElement : HTMLElement {
attribute DOMString aLink;
attribute DOMString background;
attribute DOMString bgColor;
attribute DOMString link;
attribute DOMString text;
attribute DOMString vLink;
};
Das Element HTMLTableElement ist von HTMLElement abgeleitet. Das Element stellt das HTML-Element table dar. Und enthält Eigenschaften und Methoden um Informationen aus einer Tabelle zu bekommen, oder diese Tabelle zu ändern.
Die wichtigsten Eigenschaften und Methoden:
Das folgende Beispiel (IE 5.0) zeigt die Attribute des HTMLDocument - Objektes. Das Attribut domain scheint allerdings nicht implementiert zu sein, denn der Browser zeigt hier einen JavaScript Fehler an.
Hier der Quellcode des JavaScriptes:
alert(
"document.title : "+ document.title+"\n"+
"document.referrer : "+ document.referrer+"\n"+
// "document.domain : "+ document.domain+"\n"+
"document.URL : "+ document.URL+"\n"+
"document.body : "+ document.body+"\n"+
"document.images.length : "+ document.images.length+"\n"+
"document.applets.length : "+ document.applets.length+"\n"+
"document.links.length : "+ document.links.length+"\n"+
"document.forms.length : "+ document.forms.length+"\n"+
"document.anchors.length : "+ document.anchors.length+"\n"+
"document.cookie : "+ document.cookie
);
Das W3C stellt für manche Programmiersprachen sogenannte Sprachbindungen zur Verfügung. Im Falle von Java umfasst die Sprachbindung einige Schnittstellen, die im Paket org.w3c.dom zusammengefasst sind. Das Paket steht auf der Seite des W3C zum Download bereit. Da dieses Paket nur die fertigen Schnittstellen zur Verfügung stellt, benötigt man eine konkrete Implementierung des DOM um damit arbeiten zu können. Einige der großen Firmen wie Sun oder IBM haben ihre Entwicklungen auf diesem Gebiet freigegeben und der Öffentlichkeit zur Verfügung gestellt. Der zur Zeit wohl bekannteste und auch beste Implementierung des DOM ist im Rahmen des Apache Xerces Projekts entstanden. Die Implementierung ist in Quellcode Verfügbar und kann auf der Internetseite des Apache Projektes heruntergeladen werden.
Eine andere bekannte Entwicklung auf diesem Gebiet ist das JDOM - Projekt. Das JDOM ist eine Implementierung des DOM die, die Möglichkeiten von Java konsequent nutzen soll. Es benutzt Standard Elemente der Sprache und soll die Schnittstellen damit effektiver machen.
Das folgende Beispiel zeigt das Lesen eines vorhandenen XML - Dokumentes mit der Xerces - Implementierung (Java).
import org.apache.xerces.parsers.DOMParser;
import org.w3c.dom.Document;
...
Document doc = null;
try {
DOMParser p = new DOMParser();
p.setFeature("http://xml.org/sax/feature/validation",true);
p.parse(args[0]);
doc = p.getDocument();
}
catch (IOException io) {
...
}
catch (SAXException s) {
...
}
...
Im Vergleich die gleiche Aufgabe mit der JDOM - Implementierung.
import org.jdom.input.SAXBuilder;
import org.jdom.Document;
...
Document doc = null;
try {
SAXBuilder b = new SAXBuilder(true);
doc = b.build(new File(args[0]));
}
catch (JDOMException j) {
...
}
...
In den beiden Implementierungen sind gewisse Unterschiede zu sehen. Das ist speziell auf Java zugeschnitten, so hat man bei der Implementierung auf zusätzlichen Overhead durch Fabriken verzichtet und die API so implementiert dass man hier direkt Instanzen der Klassen erzeugen und sie verwenden kann. Welche der beiden Wege, für die jeweilige Aufgabe der bessere ist bleibt dem Entwickler überlassen.
Im Rahmen des Apache Xerces Projektes ist ebenfalls eine C++ Implementierung des DOM entstanden die mittlerweile stark in der Industrie verbreitet ist.
XML ist die Grundvoraussetzung für das Verständnis und die richtige Anwendung des DOM. Fundierte XML - Kenntnisse erleichtern die Arbeit mit dem DOM und sparen so viel Entwicklungszeit.
SAX steht für Simple API for XML. SAX ist eine eventgesteuerte Parser - API für XML - Dokumente. Es ist praktisch das Gegenstück zu DOM.
Beim DOM wird das gesamte Dokument gelesen, geparst und die interne DOM - Struktur aufgebaut. In erster Linie ist das natürlich sehr bequem um mit XML - Dokumenten zu arbeiten. Diese Vorgehensweise kostet allerdings verglichen mit der SAX - Methode viel Zeit und Ressourcen. Bei der Verarbeitung von großen Dokumenten wird ein vielfaches an Speicher alloziert, da ja die gesamte DOM - Struktur auf einmal in den Speicher geladen wird.
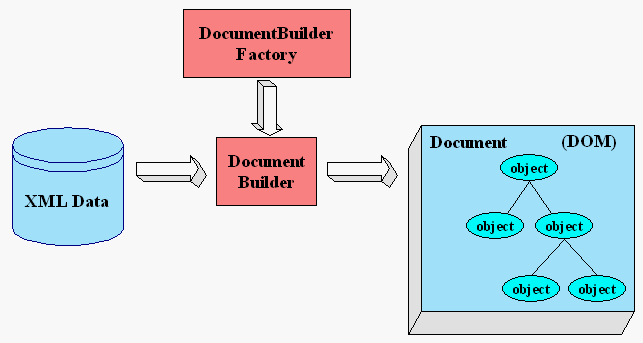
Die folgende Grafik zeigt den Lesevorgang eines XML - Dokumentes mit der DOM - API.
SAX funktioniert nach einem anderen Prinzip. SAX arbeitet Ereignisgesteuert. Beim sequentiellen lesen des Dokumentes erzeugt SAX an bestimmten Stellen des Dokumentes Ereignisse. Dem Entwickler ist es überlassen was er mit den Ereignissen macht. So können zum Beispiel nur die wichtigsten Ereignisse abgefangen und die restlichen ignoriert. Ereignisse werden bei allen wichtigen Elementen des Dokumentes erzeugt. Zu solchen Elementen gehört zum Beispiel ein Öffnendes Tag, ein schließendes Tag, ein Attribut oder einfach der Text zwischen zwei Tags. Für jede Art von Events muß der Entwickler einen Eventhandler implementieren. Dieser nimmt das Event entgegen und verarbeitet dieses.
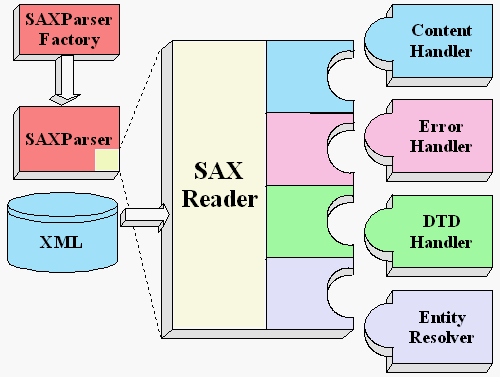
Die folgende Grafik zeigt die SAX - API und das Zusammenspiel zwischen dem XML - Dokument, der API und den eventhandlern.
XPath ist eine weiter nützliche Technologie die für die Verarbeitung von XML-Dokumenten immer mehr an Bedeutung gewinnt. XPath ist ebenfalls eine W3C - Empfehlung und wird seit 1999 entwickelt. XPath dient zum extrahieren von Daten aus einem XML - Dokument. Das Prinzip ist ähnlich wie SQl bei relationalen Datenbanken. Durch eine speziell formulierte Anfrage werden Informationen aus einem XML - Dokument extrahiert. Das Ergebnis ist ein oder mehrere Werte, je nachdem wie eine solche Anfrage formuliert wurde. Es können einzelne Werte, Attribute oder Gruppen von Knoten zurückgegeben werden. Wie der Name es schon sagt ist eine solche Anfrage ähnlich einer Pfadangabe aufgebaut. Eine solche Anfrage beginnt mit der Angabe des Wurzelsknoten, danach folgen entsprechend der Struktur und der Hierarchie des Dokumentes weiter Knotennamen bis zu der Hierarchieebene die als Ergebnis zurückgegeben werden soll. Man hangelt sich damit vom Knoten zu Knoten entsprechend der Dokumentstruktur und gibt, angelangt an der gewünschten Ebene dir Kindknoten des Knoten zurück.
Das folgende XML - Dokument stellt eine vereinfachte XML - Struktur die ein Addressbuch darstellen soll dar.
<?xml version="1.0" encoding="UTF-8"?>
<person_items>
<person id="7411">
<name>Becker</name>
<vorname>Heinz</vorname>
<vorwahl>12345</vorwahl>
<anschluss>98765</anschluss>
</person>
<person id="0815">
<name>Schröder</name>
<vorname>Gerhard</vorname>
<vorwahl>12310</vorwahl>
<anschluss>98700</anschluss>
</person>
</person_items>
Die folgende Anfrage würde alle Knoten mit der Bezeichnung name aus dem Dokument liefern
/person_irems/*
Durch den Einsatz von Aggregatfunktionen könne solche Anfragen noch weiter spezialisiert werden. Damit lassen sich Bedingungen, ähnlich der where-Bedingung bei SQL an XPath - Anfragen binden. So können Beispielsweise Werte von Attributen verglichen werden oder es kann bestimmt werden welchen Knoten man aus ganzen der Ergebnismenge nur haben will.
So liefert die folgende Anfrage die zweite Person aus dem Addresbuch.
/person_irems/person[2]